
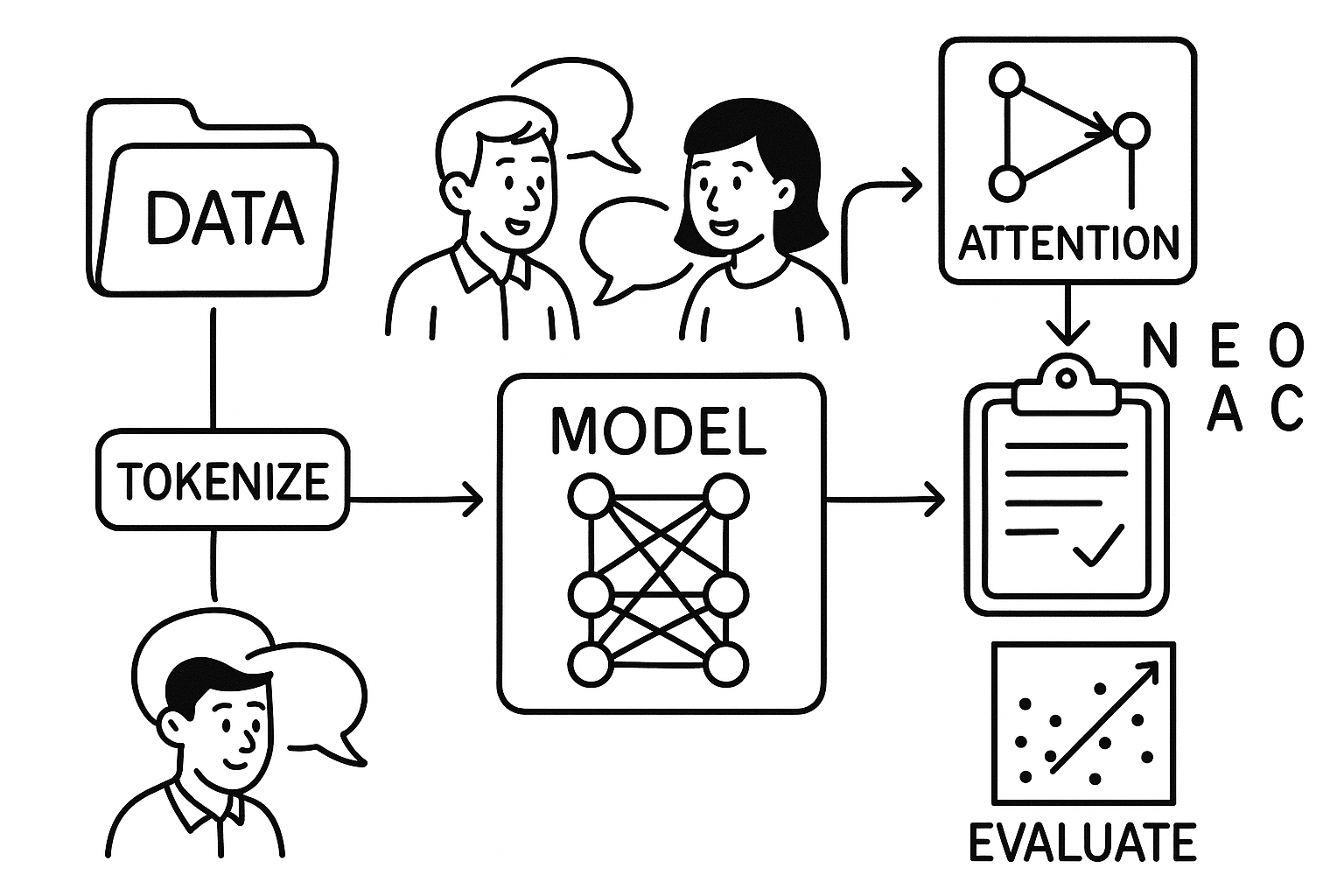
会話文からBIG5スコアを予測するアプリを作ってみた
私も、人間の性格をどう理解し、どう活かせるかというテーマには、かねてより関心を持っている一人です。
とはいえ、関心があるだけで何かが進展するわけではありませんよね。
そこで心理学の中でも比較的広く知られている「ビッグファイブ」について、書き言葉(会話文)の文章を手がかりに、自己(性格)分析や他己分析が客観的にできるツールを作れないかと、ふと思うに至りました。
自作できれば、心の研究にも多少役立つため今回のアプリ開発に取り組んだ次第です。
きなきなくよくよ、じめじめ、どろどろの消極要素が充満した潜在意識の下敷きになり糞詰まった意志の力を( 潜在意識を浄化することで )以前より出やすくした土台の上で、
向上発展方向に振り向け、やったこともない全く新しいことに淡々と取り組んで、実装させたVER4という位置づけになります。( もともとの発端はこちら )
前置きはさておき
専門用語を知らない方も多いと思いますので、まずはビッグファイブについて説明しますね。
Big5では、性格を5つの側面で捉える手法が採られています。
- 外向性(Extraversion):人と関わることに積極的か、それとも内省的で落ち着いた傾向にあるか
- 協調性(Agreeableness):他人への思いやりや共感、優しさといった傾向をどの程度持つか
- 誠実性(Conscientiousness):どれだけ計画的に物事を進め、責任を持って取り組むか
- 神経症傾向(Neuroticism):不安やストレスにどのくらい敏感に反応するか
- 開放性(Openness):新しい体験やアイデアに対して、どれほど好奇心を持ち、柔軟に受け入れられるか
これらは「良し悪し」を問うものではなく、あくまで各特性がどの程度現れているかを示す指標です。
人それぞれに違いがあり、その組み合わせによって性格の「色合い」が生まれます。
実際にチェックを行うことで、自分の特性が数値として見えるようになります。
自分では気づきにくかった部分を、客観的に見つめ直すきっかけとしてBIG5スコアを意識することは有効だと感じました。
また、性格は時間とともに変化し得るものです。その変化を捉えるための客観的な指標を持ちたいと思い、このアプリ開発に至ったというのが経緯です。
ジャーナリング等で日記をつけていたら、その簡単な会話文から性格(気質)にかかるスコアを算出し気質傾向の変化(心理の変化)を知る(追う)こともできます。
何らかのタスクの実行継続が、気質を、どう変えるかについての情報(指標)になるかもしれません。精度が高まれば、その物差しになりますから。
どんなアプリかと言いますと、以下のような入力画面がただあるだけです。
入力画面に会話文を入れるとBig5スコアを算出するという極めてシンプルなものです。
と言いますか、シンプルなものしか作れません。
以下がデモ画面です。ローカルホストで動く簡単なプロトタイプです。
会話文を入力しアプリの判定ボタンをポチッと押すと、Big5の各スコアが出ます。
サンプルの会話文やスコアの評価についても簡単に解説しますね。
▶サンプル

画面上部には “Personality Recognition Demo” というタイトルと脳のアイコンが表示され、続いて性格を予測したいテキストを入力できるテキストエリアがあります。
デモ動画では、下記のような文章を自作アプリに入力して判定させています。
「来週のプレゼンが不安で、資料は用意したものの、うまく伝えられるかどうか心配です。
初めて大勢の前で話すので緊張しますが、精一杯頑張りたいと思っています。」
アプリに、この文章を入力し、赤い縁取りの 「判定する」 ボタンをクリックすると、以下のように5つの因子それぞれについてスコアが数値で返ってきます:
- N(神経症傾向):不安やストレスへの敏感さ
- E(外向性):社交性や積極性
- O(開放性):好奇心や想像力の豊かさ
- A(協調性):思いやりや共感性
- C(誠実性):計画性や責任感
それぞれ 0〜1.0 の範囲で示され、自分でも気づきにくい性格の傾向を会話文から客観的に把握できます。
判定結果は以下のとおりでした:
| 因子 | スコア |
|---|---|
| N(神経症傾向) | 0.606 |
| E(外向性) | 0.535 |
| O(開放性) | 0.502 |
| A(協調性) | 0.598 |
| C(誠実性) | 0.537 |
各スコアの解釈を簡単にしてみます。
- N=0.606
プレゼンへの不安や緊張が反映され、「ストレスや不安に敏感」な傾向がやや強く現れています。
- E=0.535
人前で話したい気持ちがある一方、緊張も感じているため「社交性・積極性」は平均的な水準です。
- O=0.502
新しい挑戦(大勢の前での発表)に取り組む意志はあるものの、強い好奇心や独創性というよりは「まずは無難にこなしたい」という姿勢が伺えます。
- A=0.598
聴衆への配慮や、「うまく伝えたい」という思いやりの気持ちが高く出ており、共感性がやや強めです。
- C=0.537
資料をきちんと用意している点から「計画性・責任感」は平均以上ですが、完璧主義まではいかないバランス型です。
総合的に見ると、「緊張や不安(N)を抱えつつも、真摯に準備を進め(C)、聴衆への配慮(A)を忘れない」という性格の特徴がよく表れています。
あくまで一つの文章からの推定ですので、日常的な言動や別のシチュエーションでのテキストも合わせて分析すると、より多角的に自己理解を深められるでしょう。
次に 比較用の別サンプルで判定してみた結果も解説してみます。
▶ 比較用の別サンプル

例えば、こちらのような文章を入力するとします。
「昨日は友人とカフェで長時間おしゃべりして、とても楽しい時間を過ごしました。
新しい企画のアイデアもたくさん出て、ワクワクしています!」
この文章を「判定する」をクリックすると、以下のスコアが得られました。
| 因子 | スコア |
|---|---|
| N(神経症傾向) | 0.562 |
| E(外向性) | 0.614 |
| O(開放性) | 0.591 |
| A(協調性) | 0.640 |
| C(誠実性) | 0..540 |
この結果を先ほどのプレゼン例と比べてみますね。
- 神経症傾向(N)
プレゼン例では0.606とやや高めだったのに対し、こちらは0.562と不安感はやや低く、リラックスして楽しめる状態が反映されています。
- 外向性(E)
プレゼン例は0.535で平均的だったのに対し、こちらは0.614と高く、友人との会話を楽しむ様子から、社交的・活動的な傾向が中程度以上に現れています。
- 開放性(O)
プレゼン例は0.502でしたが、こちらは0.591と高く、「新しいアイデアへの好奇心・柔軟性」が際立っています。
- 協調性(A)
プレゼン例0.598に対し0.640。こちらも高めで、「相手との共感や会話を楽しむ姿勢」が伺えます。「とても楽しい時間を過ごしました」という言い回しに、人との共感や協調性が強く出ています。
- 誠実性(C)
プレゼン例0.537と同じく0.540でした。「長時間おしゃべり」という自由な時間の過ごし方から、計画性・責任感は平均的ですが一定のバランスを保っています。
比較すると、
プレゼン例 → 「やや緊張しつつも準備を重視」
カフェ例 → 「リラックスして社交・創造を楽しむ」
こうしたサンプルを並べることで、同じアプリでも入力文のニュアンスによってどんな性格傾向が浮かび上がるのかがわかりやすくなります。
今回のアプリのフォルダおよびファイル構成は以下のようなものでシンプルです。やや専門的なので関心のない方は、読み飛ばして構いません。

これも簡単に説明してみますね。
venv/
– Python の仮想環境ディレクトリです。依存ライブラリはここにインストールされていて、他のプロジェクトに影響を与えないよう分離しています。
saved_model/
– 学習済みの機械学習モデル(重みやグラフ定義)を格納しており、アプリ起動時に読み込んで推論に使います。
app.py
– メインのエントリーポイント。
streamlitで動く実行ファイルです。
仮想環境をアクティベートし、saved_model 内のモデルをロードして、Web サーバーを立ち上げ推論処理を実行し判定させるというものです。
ここからは、さらに専門的になるので、読み飛ばして構いません。(-_-;)
参考にしたのは、以下の論文及びコーパスです。
RealPersonaChat: A Realistic Persona Chat Corpus with Interlocutors’ Own Personalities
Sanae Yamashita, Koji Inoue, Ao Guo, Shota Mochizuki, Tatsuya Kawahara, Ryuichiro Higashinaka
https://aclanthology.org/2023.paclic-1.85/?utm_source=chatgpt.com
https://huggingface.co/datasets/nu-dialogue/real-persona-chat?utm_source=chatgpt.com
今回、会話文からBig-Five の5要素を同時回帰し、出力するアプリを作る際に機械学習モデルに訓練させたデータについて解説します。
これについては名古屋大学などで公開されている「RealPersonaChat」をベースにした、対話テキストとBig 5性格スコアをペアにしたコーパスから作成しました。
なぜ、この論文およびコーパスを参考にしたかと言いますと、上記の研究は話者の多様性拡充とモデリングの二重課題を同時に解決しています。
また、対話における人格認識性能を大幅に向上させており、着眼や発想そのものが、鋭いといいますか、よく練りこまれた優れた研究だと思ったからです。
名古屋大の RealPersonaChat コーパス(対話 JSON と interlocutors.json)から、「対話+話者ごとの Big-5 スコア」を紐づけ、まとめて機械学習モデルに訓練させるCSV データセットを段階的に作り、学習用・検証用・テスト用に分割する、という一連の処理を行いました。
データも最初は1000件から始めています。kaggleの無料枠GPUで扱えるか不安でしたから。
( 例のメモリーオーバーでエラーというのは、個人レベル研究で節約しながらkaggleを使って実装を試みる際に、あるあるですよね )
1000件のCSVでモデル学習をしkaggleノートでメモリーオーバー
最後は全てのデータを使い機械学習モデルの学習・評価に使えるCSV 形式のデータセット( train.csv、valid.csv、test.csv )を慎重に、無料枠内で作れることを確認しながら作製。
そうして訓練および評価をしています。
回帰予測するモデルを学習・評価するCSVデータの構成は、以下のようなものです。
元の対話ファイル名(例:12248.csv)。
speaker_id 発話者(ペルソナ)のID(例:DL,EDなど)。
dialogue
2人(SPK1, SPK2)のやりとり全体。[SPK1]…[SPK2]…という形式。
n, e, o, a, c
各行の“ペルソナ”に対応するBig 5の連続値スコア(およそ1〜7程度のレンジ)etc。
こういうデータをベースにLLMを訓練し回帰予測するモデルを作りました。
予測モデル構築については名大でサンプルコードも提示してくれています。
↓ ↓ ↓
https://github.com/fuyahuii/Personality-Recognition-on-RealPersonaChat
ただし訓練のためのコードについては、私には荷が重すぎるといいますか、参考にはさせていただきましたが高度すぎました。
流石にコードが1000行近いとデバッグがきつくなっていきます。
最も大きな懸案事項は、kaggle無料枠で出来る範囲のなかでやっている以上、メモリーオーバーを回避しながらやり切れる自信がありませんでした。
(これがネックで挫折を幾度も経験しています)
無料枠かつ実装をメインにしている以上、あまりリスクは取れないと思ったので訓練ができて、ある程度の精度が出ればよいという簡易版(妥協VER)です。
kaggleノート(無料枠)でモデルを作るのにメモリーオーバーにならないように最初は1000件→5000件→全データと徐々に増やしました。
1000件のデータで訓練させた時の妥協コードを以下に掲載しておきます。
上記コードを1枚の画像にしたら以下のような概念図になります。
最終的に13583件で訓練させた結果は以下でした。
( 幸い<ありがたいことに>kaggleノートで無料枠でできました。GPUはT4×2で約1時間半の訓練時間)
結果を抜粋したものが以下です。
Epoch 1: Train 0.1411 Val 0.1348
Epoch 2: Train 0.1324 Val 0.1336
Epoch 3: Train 0.1276 Val 0.1301
✅ モデルとトークナイザーを保存しました: /kaggle/working/saved_model
Test Loss: 0.1303
Metrics: {'pearson': [0.28096247, 0.267798, 0.37978506, 0.2798457, 0.20112357], 'spearman': [0.26343786362841604, 0.25263496687695386, 0.30909098878564667, 0.26950801889594816, 0.20679605998337286], 'acc05': [0.6449595290654894, 0.6865342163355408, 0.7501839587932303, 0.862766740250184, 0.6181015452538632], 'bal05': [0.5895557107604524, 0.5234872033416204, 0.5809722733274172, 0.5253332079401104, 0.5481965174129353]}
実用性の観点から結果を概観すると
相関(Pearson/Spearman)
相関係数が 0.2〜0.4 というのは「弱い〜中程度」の予測性能で物足りません。
とくに「神経症傾向」や「開放性/協調性」は、低い精度です。
二値分類的評価(Acc@0.5/BalAcc@0.5)
単純閾値(中央値など)で分けたときの正解率(Acc)は高く見えますが、クラス不均衡を勘案した BalAcc はほぼ 0.5 ~ 0.6。
BalAcc=0.5 はランダム予測と同程度ですので、実運用で「この人は協調性が高い」などと判断するのはリスクがあります。
絶対値としてはまだ信頼しづらく改善が必要です。
とは言え同じモデル・同じ条件で繰り返し測れば個人の「変化」を追うには使えるといったところでしょうか。
継続的な改善が必要とは言え何らかのタスクの実行継続が、実践者の気質を、どう変えるか?について、日記などの書き言葉や会話文から推定し数値化し評価材料にする際に、
客観的な指標になり得ます。
ですので今回のコンセプトに、一応は合っています。
ということで、今回の記事を概観しながら再度、用語解説しながら再度説明しますが、
ビッグファイブとは?
ビッグファイブとは、「人の性格を5つの視点で捉えましょう」という心理学の有名な考え方です。
その5つとは――
外向性(社交的かどうか)
協調性(思いやりや優しさ)
誠実性(計画性やまじめさ)
神経症傾向(不安やストレスへの敏感さ)
開放性(新しいもの好き・好奇心)
それぞれが強い・弱いというより、「自分はどの傾向がどのくらいあるのかな?」を知るための指標です。
このアプリでできること
今回作ったアプリは、「自分の文章から性格傾向(ビッグファイブの5項目)を自動で数値化して見せてくれるツール」です。
例えば――
日記やSNSの文章
仕事や友達との会話文
などをアプリにコピペして、ボタンを押すだけ。
すると「あなたのこの文章は、●●が高め、▲▲は平均的、■■はやや低め」といった感じで、5つの項目それぞれのスコアが数値で出てきます。
どんな発見や役立ちがあるの?
自分でも気づいていなかった性格の傾向が見える!
「意外と社交的な一面があるんだ」「普段よりも不安を感じているかも」など、自己発見につながります。
文章ごとの違いもわかる
仕事の悩みを書いた日記と、友達と遊んだ日の感想文では、スコアが変わることも。
その時々の心の状態や、場面ごとの自分の傾向が見えて面白いです。
気持ちや性格の「変化」も追える
たとえば毎日ちょっとした日記を書いて記録しておけば、時間とともに「今の自分はどんな傾向が強まっている?」といった心の変化も客観的に振り返ることができます。
自分を知るヒントや、コミュニケーションの工夫に
「最近ストレスを感じやすいかも」と気づけば、ちょっと休憩を意識したり。
「もっと好奇心を生かして新しいことに挑戦しよう」など、毎日の過ごし方のヒントにもなるかも。
一言で、まとめると、
「会話文から自動でビッグファイブ性格スコアを算出するWebアプリ」を、実データと機械学習モデルを用いて構築・評価した備忘録的記録。
精度向上の余地はあるが、自己分析や変化追跡のツールとしての可能性を示してはいる。(あくまで主観です)
といったとこでしょうか。