
今回この記事を執筆しようと思ったのは、以下のアンケ-ト記事が発端です。

私の気のせいかもしれないのですが、この手のヤ●ーのアンケ-ト調査では、
不安をあおってアクセスを稼ぐために
「(景気は) 悪くなっている 」という結果になる傾向が強いように思っています。
( YA●OOは、結構よい記事を書くケ-スもあるとは言え )
こういうやり方は、なんだか残念で嫌だなと思うことがあるわけです。
とは言え企業活動しているんだし、視聴率や売上を意識したメディアが煽情的かつ不安を喚起せしめるネガティブなニュースで
ユ-ザ-の注目と関心を奪うシステムは、今のとこ、どうしようもないでしょう。
こういう手法だとユ-ザ-の反応率が上がって影響力を行使でき都合がよいということが、
莫大なお金をかけた緻密な計測で確かめられているから、そうしているのでしょう。
と言うことは、私たちユ-ザ-が、こういう様々な刺激に恬淡と向き合いメディアリテラシーを高める必要があるのでしょう。
衝撃的な見出しや炎上を狙ったコンテンツに惑わされない、
またニュ-ス断ちなどを時々するユ-ザ-が増えれば増える程、
効果が少なくなって記事のあり方も根本から変わっていくかもしれません。
実際、´ニュ-ス断ち´とかも良いかもしれません。
あるいは、
ヤ●-ニュ-スに限らず、様々な刺激が私たちの感覚にまとわりついて、
注目と関心を奪おうとする世相にありますので、
それらすべてから逃れ静謐な場所に逃げ込むことができる瞑想も、ある意味では、良いかもしれません。
ただ、そういうのは生産性がありません。
そこで(個人の力は強くなくても)私でも何かできることはないか?
ちいさなハチドリのちいさな一滴だと、ふと思い直すに至り
今回、coincident indexを予測する機械学習モデルを勢いで作ったというのが、背景の動機になります。
(不徳にも)怒りを覚えた成り行きで学んでいくうちに、この分野に幾ばくか詳しくなり、
少しばかり教えられるようになったというのもあり日曜大工的に取り組みました。
結果的に三カ月予測でAvarage MSE 〔 0.7~1 〕の精度のモデルを作ることが出来ました。
やってみたかったことだったので、作れてよかったです。
以下は、2023年10月から12月を検証用にして予測値と実際の誤差を表した図です。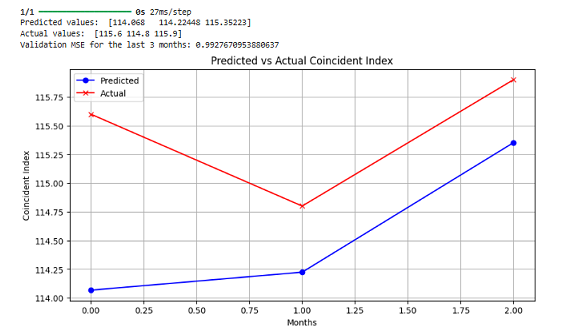
欠損値があったので2023年12月までのデ-タにして、そのうち最後の三カ月を検証用に用いて結果を予想し比較したものです。
ちなみに2024年3月までの欠損値をランダムフォレスト回帰分析で埋めて上記のモデルで
4月から6月までの一致指数を予想させたら、下がり傾向でした。
( よってYA●OOのアンケ-ト予想と同じですね。残念なことに )
今回、機械学習モデルを作る際に参考にしたのは、
以下のURLからDLできるPDFの報告書です。
内閣府景気動向指数の先行系列に基づく機械学習を用いた短期経済予測
水門 善之, 坂地 泰紀, 和泉 潔, 島田 尚, 松島 裕康
https://www.jstage.jst.go.jp/article/jsaisigtwo/2019/SAI-034/2019_04/_article/-char/ja/
これを参考にしたのは以下の理由からです。
1.日本の景気の先行きを示すのに使われる11種類の国の統計データを使って予測モデルを構築していて元デ-タの信頼性が高いこと
2.RNN、LSTM、MLPという方法を使っていて、時系列モデルとしてシンプルかつ妥当で、これらをベ-スに色々試せそうだと思ったこと
※実際、技術報告を参考にはしましたが、RNNではなく勾配消失に対応しやすいとされているGRUモデルで新たに予測モデルを構築しています
3.作った予測モデルがどれだけ正確かを、いくつかのテストをして確かめておりシンプルながら優れた報告書だと思ったこと
4.データの入手先やモデル構築の仕方など詳細が明示されていて比較的、参考にしやすかったこと
以上が挙げられます。
そこで、まずPDFを参考に以下からデータの入手をしました。
内閣府ホーム 内閣府の政策 経済社会総合研究所 景気統計 景気動向指数
そして、報告にあるように1985年1月からの景気動向指数を予測するモデルをL1~L11の特徴量を使って作るために
以下のようなCSVファイルを作成しました。

( 一部抜粋 )
ただし、いくら、詳細かつ簡潔に、資料の出典や予測モデルの組み方などを明示してくれている報告書であっても、どの数字を訓練および検証デ-タにしたか、正確にはわかりませんでした。ですのでリンク先の景気統計の生デ-タから3種類のデ-タを作っています。
そのなかで予測精度が高かったのが上記のデ-タでしたので便宜上、以降は、このデ-タで、どのように予測モデルを構築していったかを説明していきます。
csvファイルも、景気動向指数を予測するモデルの基本デ-タ
上記にFEH_2405b.csvというファイル名で置いておきますので、kaggleノ-トに、このCSVファイルをアップして以下に述べる訓練をさせれば、今回の小さな実験について、ある程度までは再現できるかと思います。もちろん訓練誤差はあると思いますが。
具体的には、以下の流れで一連のpythonコードを実行し、モデル構築しています。
何からやったかと申しますと、何はなくとも、まずは作成したデータの概要および分布の把握です。
以下のpythonコードでデータの欠損の有無や概要を把握するようにしました。
※欠損があると、コ-ディングがやや煩雑になりますので欠損が無いことは事前に目視確認はしていましたが再確認も兼ねて行っています。
上記コードは、CSVファイルからデータを読み込み、データの詳細を確認するために使うものです。データの全体像を把握するために、データの種類や統計情報、先頭の5行を表示します。これにより、どんな傾向かを全体的に確認できます。
コ-ドを実行した際の結果は、以下のとおりでした。
Data Information:
RangeIndex: 468 entries, 0 to 467
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 時間軸(月次) 468 non-null object
1 (先行)_一致指数トレンド成分 468 non-null float64
2 (先行)_L1最終需要財在庫率指数(逆サイクル) 468 non-null float64
3 (先行)_L2鉱工業用生産財在庫率指数(逆サイクル) 468 non-null float64
4 (先行)_L3新規求人数(除学卒) 468 non-null int64
5 (先行)_L4実質機械受注(製造業) 468 non-null int64
6 (先行)_L5新設住宅着工床面積 468 non-null int64
7 (先行)_L6消費者態度指数 468 non-null float64
8 (先行)_L7日経商品指数(42種) 468 non-null float64
9 (先行)_L8マネーストック(M2)(前年同月比) 468 non-null float64
10 (先行)_L9東証株価指数 468 non-null float64
11 (先行)_L10投資環境指数(製造業) 468 non-null float64
12 (先行)_L11中小企業売上げ見通しDI 468 non-null float64
13 Coincident Index 468 non-null float64
dtypes: float64(10), int64(3), object(1)
memory usage: 51.3+ KB
Data Description:
(先行)_一致指数トレンド成分 (先行)_L1最終需要財在庫率指数(逆サイクル) (先行)_L2鉱工業用生産財在庫率指数(逆サイクル) \
count 468.000000 468.000000 468.000000
mean 0.061981 79.085256 76.665171
std 0.174652 9.132549 11.295073
min -0.382020 64.600000 60.900000
25% -0.064747 72.400000 68.600000
50% 0.045059 77.750000 73.100000
75% 0.171571 83.125000 83.500000
max 0.616293 117.500000 121.200000
(先行)_L3新規求人数(除学卒) (先行)_L4実質機械受注(製造業) (先行)_L5新設住宅着工床面積 \
count 4.680000e+02 468.000000 468.000000
mean 6.695365e+05 351543.500000 8486.025641
std 1.697801e+05 64205.938977 2204.506889
min 3.630300e+05 196846.000000 5043.000000
25% 5.284455e+05 298300.000000 6296.500000
50% 6.393535e+05 346625.000000 8707.500000
75% 8.296452e+05 396426.250000 10041.500000
max 1.004750e+06 513556.000000 14125.000000
(先行)_L6消費者態度指数 (先行)_L7日経商品指数(42種) (先行)_L8マネーストック(M2)(前年同月比) \
count 468.000000 468.000000 468.000000
mean 39.095085 152.638891 3.983547
std 4.601377 36.151152 2.965297
min 21.800000 99.203000 -0.600000
25% 36.275000 121.365250 2.200000
50% 39.200000 152.125000 3.000000
75% 43.000000 175.352750 3.900000
max 47.100000 258.467000 13.200000
(先行)_L9東証株価指数 (先行)_L10投資環境指数(製造業) (先行)_L11中小企業売上げ見通しDI \
count 468.000000 468.000000 468.000000
mean 1466.110321 1.852949 2.870085
std 431.638887 1.902807 12.727084
min 730.120000 -4.560000 -63.500000
25% 1155.287500 0.547500 -3.150000
50% 1476.190000 2.045000 4.500000
75% 1709.260000 3.530000 11.300000
max 2859.570000 4.810000 28.400000
Coincident Index
count 468.000000
mean 108.527350
std 9.768517
min 83.400000
25% 100.675000
50% 109.500000
75% 116.600000
max 125.300000
First 5 Rows of the Data:
時間軸(月次) (先行)_一致指数トレンド成分 (先行)_L1最終需要財在庫率指数(逆サイクル) \
0 1985年1月 0.143024 74.4
1 1985年2月 0.078596 74.5
2 1985年3月 0.110165 74.2
3 1985年4月 0.103419 74.1
4 1985年5月 0.108898 72.8
(先行)_L2鉱工業用生産財在庫率指数(逆サイクル) (先行)_L3新規求人数(除学卒) (先行)_L4実質機械受注(製造業) \
0 65.4 402179 281650
1 66.6 411234 299976
2 67.1 400606 273846
3 67.4 409642 288997
4 67.7 407704 302758
(先行)_L5新設住宅着工床面積 (先行)_L6消費者態度指数 (先行)_L7日経商品指数(42種) \
0 8545 43.8 182.301
1 8571 43.9 181.652
2 8941 44.0 181.003
3 8888 43.8 180.980
4 8841 43.5 179.742
(先行)_L8マネーストック(M2)(前年同月比) (先行)_L9東証株価指数 (先行)_L10投資環境指数(製造業) \
0 7.9 927.20 -0.14
1 7.9 941.18 -0.55
2 7.9 994.51 -0.48
3 8.4 972.46 -0.26
4 8.3 983.88 -0.14
(先行)_L11中小企業売上げ見通しDI Coincident Index
0 12.7 91.8
1 18.6 91.5
2 15.1 91.4
3 13.1 92.4
4 10.9 92.4
次に機械学習モデルがデータを学習しやすくするには、どういう処理が必要かを検討するのに、各特徴量のヒストグラムを表示させました。
そのコ-ドが以下です。
上記コードは、CSVファイルから数値データを読み込みL1~L11(ただし今回使わなかった一致指数トレンド成分も含む)の各特徴量のヒストグラムを表示させたものです。日本語フォントを設定して、グラフのタイトルや軸ラベルが日本語で表示されるようにしています。
最終的に、データの分布を視覚的に理解し、前処理でスケ-ル調整の参考にするためにグラフを描画しています。
結果は以下でした。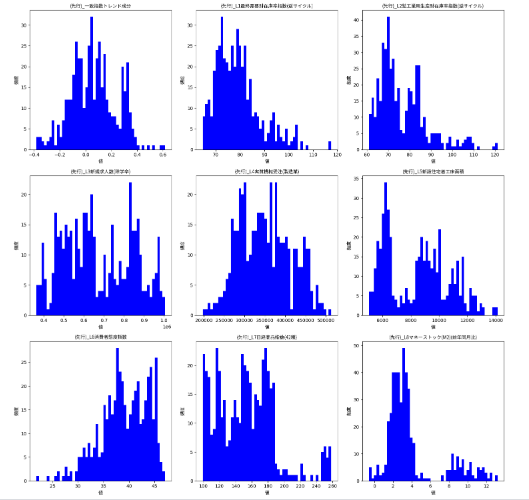

続けて日本の経済指標「一致指数(coincident index)」の時系列変動をグラフに描くコードが以下です。これにより、1985年1月以降の経済の動向を時間の経過とともに視覚的に確認できます。
コ-ドを実行すると以下の結果でした。デ-タ欠損処理などの関係で2023年12月までのデ-タの描画になります。

次にヒートマップを表示させるコ-ドを参考のために準備しました。
ヒートマップは、データの相関関係やパターンを色の濃淡で表現する図で、数値の大きさに応じて色を変えることで各特徴量の関係や影響度の強さを視覚的に理解しやすくします。
コ-ドは以下のとおりです。
上記コ-ドの実行により以下の結果が得られました。
ここまでの前準備をし、ラベルのスケ-ルやデ-タ構造などを把握したうえでモデル構築していきます。
以下のコードは、過去約40年分の経済データを使って未来の経済指標を予測する機械学習モデルを作成し訓練および検証をするコードです。
構築できたコ-ドを表示していますが、試行錯誤を繰り返しています。
工夫したのはデータを標準化したことと、交差検証を通じてモデルの予測性能を評価するコ-ドにしたことです。
評価する指標として平均二乗誤差を計算し、予測結果と実際のデータとの関係をグラフで表示させています。
初期設定で層のユニット数を150、活性化関数をtanhにしたのは参考にしたPDFに倣って、そうしました。
評価手法も論文と同じにしています。
PDFの予測手法を基本、参考にはしましたが、再現できてるかは不明です。
また報告ではRNNやLSTMで予測していますが、新しい試みとしてGRUで新しくモデル構築を試しています。
上記のコ-ドを実行した際、以下の結果が得られました。
抜粋してみますね。
Average MSE over all folds: [0.87271412 0.97465826 1.28069774]
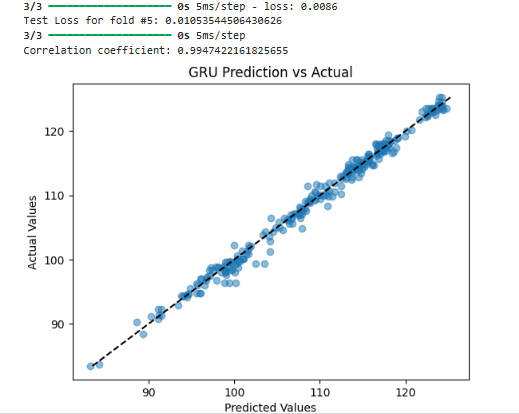
上記を見ると、Average MSE over all foldsは、0.87~1.28です。
やや過学習気味ですが、よく適合しています。
そこで、上記のGRUモデルをベースにハイパーパラメーターチューニングにより高精度化していきます。
以下のコードは、過去約40年分の経済指標データを用いて未来の経済指標を予測するための機械学習モデルを訓練するコードです。
CSVファイルを読み込み、ラベルなどを標準化後、複数の設定でモデルを自動で試すハイパーパラメータチューニングを行い、
最適な設定でモデルを再訓練するコ-ドになります。
最後に、様々な設定でのモデルの性能を評価し、平均二乗誤差(MSE)を計算して性能を比較します。
この結果から、今回のデータの実験系では、
GRU 200, model.add(Dropout(0.15))
learning_rate=0.000711638351234406),
このチューニング結果が良好と出ました。
よって、このモデルで再学習させ予測させます。
以下の動画を前振り(マエフリ)で見れば、動画下のコ-ドの概要について理解しやすくなるかと思います。
上記のコードは1985年から約40年分の経済データを使って未来の経済指標を予測するためのニューラルネットワークモデルを構築し、訓練するためのコードです。
データは標準化され、ハイパーパラメータチューニングを通じて探したモデルの構成を採用して、それを組み込んでいます。層のユニット数200、ドロップアウト率(15%)、および学習率(0.00071・・)が選択されていることに気づくと思います。他の構成は、これまでと変わりません。
活性化関数はtanhで固定しました。
1分動画でも解説しているように交差検証でモデルを訓練し、平均二乗誤差で予測の精度を評価させています。最後に、予測結果は実際のデータと比較してグラフで示され、予測の妥当性を検証しています。
上記コ-ドの実行により以下の結果が得られました。
Average MSE over all folds: [0.77608843 0.73390224 0.98772539]
チュ-ニングによって得られたモデルのほうがAverage MSEが低くなっており精度が高まっています。
さらに予測値と実測値との検証結果も良好です。
最後に上記のモデルを使って、どの経済指標が予測に最も影響を与えるかを勾配計算により調査します。
上記のコードでは、1985年から約40年分の経済データを使って将来の経済指数を予測するGRUネットワークモデルを訓練し、
比較的うまく適合したモデルが、どの特徴量を重要と判断しているかを勾配を通じて評価します。これにより、どの経済指標が予測に最も影響を与えるかが明確になります。
上記コ-ドの実行結果を抜粋したら以下の結果が得られました。
L3 、L2、L7、L11がcoincident indexに強い影響を与えていることがわかります。
こういうのは機械学習モデルを構築することで改めてわかってくることです。
ゆえに今回のモデルに限らず、更に、よりよいモデルが出来れば、(逆算することで)政策立案する際に、
どこに注力すべきか?という大枠の指針にもなり得ます。
こういうAIモデルを駆使した逆算手法で人々の暮らしをよくする政策立案の基礎研究をするのも、見逃しがちで地味ですが案外重要なことかもしれません。
で、以上を踏まえて、現況を把握しつつ予測する力をつけるには、どうしたらよいのでしょうか?
勿論、上述したようなpythonコ-ドを書いて機械学習モデルを構築し予測が出来たほうが良いでしょう。
機械学習のコ-ディングなどは出来るようになったほうがAI時代の備えとして、大事な事と思います。
とは言え、こういうことに全く興味もないし取組むのに時間がないという方も多くいらっしゃるでしょう。
それでも、景気の流れ(フロ-)について、知見を持っておいたほうが良いですよね。
そういう場合でも、最後の結果を踏まえて、知見を得ることは出来ます。
というのも、機械学習モデルの勾配計算をした結果、以下の先行指数
L3新規求人数(除学卒) 、L2鉱工業用生産財在庫率指数、L7日経商品指数(42種)
L11中小企業売上げ見通しDI
以上の4つの先行指数が、予測モデルに与える影響が比較的強いということがわかっていますよね。今回、試験的に実装したモデルでは。
よって、これらの先行指数を中心に国のデ-タなどで確認し、増減を精査したら、
冒頭に挙げたアンケ-トなどの結果だけに頼らない判断の材料が、一つ増えるのではないでしょうか?
景気の波は避けられないでしょう。よい時は、よいなりの対応をし、よくない時は、よくないなりの対応をする必要があります。
雨が降りそうか、そうでないか、傘の用意が必要か、判断のための材料が、幾つかあったほうが良いでしょう。
その判断のためのデ-タは前掲したように、現況を含めて以下にも公開されています。
上記デ-タをベ-スに構築した今回のモデルも、活性化関数を変更したり、他のモデルを試したりすれば、もっと汎用性の高い優れたモデルが出来るかもしれません。
デ-タを追加していけば、さらに高精度になるかもしれません。
それに、このモデルをベ-スに、あとはCSVファイルに新しく国のデ-タを追加していけば将来予測も可能になることは、勘の良い方なら、すぐに合点していただけるかと。
(欠損値については、幾ばくか誤差は出るでしょうが重回帰分析やランダムフォレストなどの回帰分析で埋めることも出来ます)
国の優秀な官僚が日本の為にと深夜残業を繰り返し・・
苦労を重ねて各部局と調整しながら取りまとめて決裁伺いを出し、幾つもハンコを貰って
(尤も今は部局によって変わるとはいえ電子決裁が大半でしょうが、労力はさほど変わらないでしょう)
苦労して公表したであろうデ-タを活用しない手はないでしょう。
こういうアンケ-ト調査も傾向を知るのに、よいかもしれませんが
それよりは、coincident index( 一致指数 )の数値の推移をチェックするほうが、よほど客観的で冷静な判断材料になるのではないでしょうか?
PS
個人的には、以下の図で1985年以降の景気の波、流れを大局的に把握しておくのも案外と良い気はします。
今回、GRUで予測モデルを構築するプロセスで知ったのは収穫でした。
こういうのを探求する中で、こういう現象的な目に見える景気の流れの背後の根源みたいのにフォ-カスし思いを馳せられたら、もっと良いのだろうなと思います。
非エンジニアでノンプログラマ-でもコ-ディング出来た理由-ネタバレ(カラクリ)
ここでも書いてるように私はノンプログラマ-で非エンジニアです。
現時点でもお世辞にもコ-ディング力は、さほどありません。
それでも、こういうコ-ディングが出来るのは、コ-ドを読む力がついたのと、この分野に少し詳しくなって
GPT4やClaudeなどのAIアシスタントに的確な指示が出せるようになったからです。
こういうのは、ある意味プロンプトエンジニアリングの亜流に当たるのかもしれません。
何て言いますか、これは課題を、こちらで咀嚼し整理し人に明確に意図を伝えて、
指示されたアシスタントの方が仕事をしやすくするための一般的な管理およびコミュニケ-ションスキルみたいなものです。
AIも人も変わらないと言いますか。
してみると、(私はそこまで、そういう力はないですけど)
ここまでAIアシスタントが進化してるのを目の当たりにし、
実際に進化速度の加速が予測されますので
ある一定レベルのプログラミング力は必要でしょうが・・・
プロンプトエンジニアリングとかもAIの進化で陳腐化する可能性がありますね。
それより、やりたいことを明確にし課題を細分化し交通整理すると言いますか・・
アシスタントの方に、やりたいことを伝えて
円滑に仕事をしてもらうためのやってほしいことの明確な指示および管理、監督および調整、
細分化やコミュニケ-ションスキル、さらには質問力
あるいは自己対話スキルがある方のほうが
コ-ディングは、そこそこでもAIを使いこなせる潜在能力は高いのではないかと言う気がします。
非エンジニアでノンプログラマ-でもコ-ディング等について
ChatGPTやClaudeなどのAIアシスタントの力を借りれば
呆れるくらい敷居が下がっている事が体感できるのではないでしょうか?
そう思えたなら、記事として作った甲斐があるというものです。
それに、仮に上記の技術論文で用語理解が曖昧でわからなかったら質問テンプレ-トの方法やAtkinson's Deep 12Qなどのツ-ルで、用語を入力したら、時間をかけずに相当に掘り下げた知見を得ることも出来ますし・・
(Atkinson's Deep 12QもGPTsビルダ-で自前で作りましたので公開しておきます。無料の場合はイラストなどの描画が出来ないなどの一部制限はありますが無料枠でも結構使えると思います)
ここからは、雑感と言いますか独り言みたいなものですが、
chatGPT4(3.5)などのAIアシスタントは、使いこなせば生産性および効率は、相当に向上するのではないでしょうか?
ChatGPT4などは、ほんと難しいことを簡単にしてくれるという意味で、運勢学的にもツキのあるツ-ルでしょう。
chatGPT4やClaudeなどを上手く使って、こういうPythonでの機械学習コ-ディングに慣れてくると・・・
JavascriptもPythonと構造が似てるので、そっちも修得が容易になります。
非エンジニアでも、なんとなく面白そうだと思ったOpenDevinの実装が、やってるうちに出来てしまったりもします。
あるいは、たまたまスポ-ツ観戦でスマホで撮影した試合中動画について
yolov5sモデルでボ-ルや人などを検出させたものを簡単に作れたりします。
( ただ、これは事前訓練済みのものを適用するだけだから簡単なので )
少し応用させたものだと、TARAN MARLEY氏の物体検知(Yolo V5 Object Detection)のコ-ドを参考に
少しだけ弄って以下のようにタイヤ検知のモデルを作り・・
kaggleノ-トで訓練したカスタム・モデルをベ-スに以下のように動画内の走行車のタイヤを選択的に検知させることも出来ます。
以下のデモ動画は、上記のバレ-の試合から作ったデモ動画よりかは、少し難しくて、こういうのやってる方から見たら、「 これを作った方は、kaggleやpython機械学習に慣れていて、結構、こういうの作り慣れてるみたいだ 」と思うのではないかと。
興味を持ってもらいたくて日曜大工的に作りました。
とは言え、こういうデモ動画を見ても
「すぐには役立ちそうにない・・」。
という声が聴こえてきそうです。
ですけどノンプログラマ-かつ非エンジニアで、独学でもClaudeやchatGPTを介して
機械学習コ-ドを読むことに慣れて、自身を少しずつレベルアップさせていったら
割に短期間に作れてしまうというのがポイントです。
更に、こういうのより簡単なPythonを使ったEXEL自動化やスクレイピングの応用。
簡単なアプリなどが、何となく慣れで作れるようになるというオマケ特典がつきます。
( 例えがよくないですけど高校の数学の教科書の章末問題が解ければ、それより簡単な基本問題は、大概出来るのと同じ理屈です )
そうなると、、もはや古典的手法になってますけど
7つの習慣の時間管理のマトリクスのうち、以下の赤枠で囲んだ
「 緊急で重要なタスク 」や「 緊急だが重要ではないタスク 」
これらを業務などのなかで洗い出して
状況に応じて少しずつPythonのスクリプトを組み込んだものに移行させることで
省力化出来るケ-スが増えます。
特に創造性や閃きを必要としない単調で面倒な事を任せるということになるでしょう。
そうなると、第二領域に使う時間が増えるので生産性は上がるでしょう。
また、こういうスキルは、組み合わせるなどしたら人々の役に立って収益を上げることになるものを生み出せる´ 底支えのスキル ´にもなるでしょう。
とは言え、やはり心身統一法を実践し、不要残留本能を鎮めつつ集中力や粘り強さを耕している方のほうが、
こういうのを作製する際にもアドバンテ-ジがあると思います。
ある意味、口述書を知らない方と知って実践している方では、
初期段階で同じくらいの能力であっても不要残留本能が、
必要なのに、嫌に感じることから逃げようと働くため、鎮める力を培ってないと不公平な差になる気がします。
実際私は、今回の件を手がけた際に技術報告書を参考にGPT4の力を借りて
GRUという新たなモデルでコ-ドを一から作製するのに3日と半日かかりましたけど、
上記のト-タル数百行の一連のコ-ドを完成させるのに300回以上エラ-が出て失敗し
その都度AIアシスタントに質問しデバッグしてますから。
忍耐力がないと心折れる方も出てくると思います。
初期段階で同じくらいのレベルだったとして同じ程度のスキルがある二人の方がいたとして
心身統一法を実践し、(実践してない方から見たら)アンフェアな力を培って不要残留本能を鎮めて
眠れる才能を少しは起こしているAさんと知らず実践してないBさんでは
紙一重で結果は大きく違ってくるのではないでしょうか?
私の事例で言えば、表面意識は、マイナス化している自覚はなくても
潜在意識が負け犬化していた以前の私だったら、こういうスキルも修得できてなかった可能性があります。
ちなみに今回の小さなプロジェクトを為すのにも、私は簡単ながら、ゴ-ル(目標)や手順書を手書きで紙に書いています。
手で簡単に書かないで取り組んだ小さなプロジェクトもありますが、
簡単にでも書いたほうが、潜在意識に与えるインパクトが書かないよりかは新しく増えるので、うまくいきやすいと見ています。