サイトテ-マとは、やや離れますが、機械学習分野は、今後益々重要な分野になるのは火を見るより明らかです。
それに新しいことに取組むことは脳の活性化にも良い影響を与えます。
ですので今回の新記事も、サイト読者に、こういう機械学習分野に興味を持ってもらいたくて、新たなジャンルに取組んだ時の記事同様に機械学習関連にしました。
ここ最近の生成系AIの進化は目覚ましいものがあります。なかでもオ-プンソ-スとして私が非常に注目をしているのがOpenDevinです。

OpenDevinは、自律型AIエンジニアです。DEVINがモデルとされています。
今回、OPEN DEVINの実装に取り組んだ目的は、、、そもそもこのペ-ジを執筆している私自身が、このジャンルは手探り状態でして、
正直な本音、この分野については教える程の資格があるのか?、というような立場です。
それでも、こういう新ジャンルのスキルが増えて扱い慣れていくのは面白いですし、
chat gptが機械学習コ-ディングなどの学びを加速できることを経験で知ったので、
今回も、このジャンルで書いてみます。
もちろん、こういった生成系言語モデルや周辺のエンジニアスキルを扱うことに慣れるというのは表面的な力でしかない、というのも弁えた上で、、と言うことになります。
そういう前置きで、この記事では、オープンソースのOpenDevinの特徴、そして実際にロ-カルPCに導入し使ってみた感想や導入手順を簡単に紹介してみます。
OpenDevinの紹介:
OpenDevinは、単一のプロンプトから、ほぼ自動でアプリケーション全体を開発できる生成系AIソフトウェアです。
ターミナル、コードエディター、ブラウザーを一つのインターフェースに統合し使うことが出来ます。
特徴
オープンソースであり、OpenAIやCloud3など複数のエージェントやモデルをサポートします。
エージェントは、自律的に行動し、環境と対話できるソフトウェアプログラムです。
Python、JavaScript、Go、Rustなど、さまざまなプログラミング言語に対応しています。
どちらを使うべきかは、ユーザーの好みやスキルレベルによって異なりますが
OPEN DEVINはコマンドラインツールとGUIインターフェースの両面からプログラムを実行する機能があるのも特徴です。
実装例
結論から言いますと、OpenDevinは、わずか0.2ドル、2分でメモアプリを開発してくれました。音声認識変換アプリは、0.8ドル、3分でエラ-なく運用可能なアプリを開発してくれました。
実装し使ってみた正直な感想を箇条書きにしてみます。
自己完結で開発:
プロンプトからコードを自動生成し、簡単なアプリなら効率的に実行でき完結させます。
コストパフォーマンスが高い:
GPT4-turboなどの高度なモデルほど精度が高まりますがト-クン数に応じたAPIの単価が高くなります。
例えば、今回作成依頼した音声認識変換アプリ・・・
この開発費用が0.8ドルを高いと見るか、それとも安いと見るか・・感覚は人それぞれなのかもしれません。
API使ってるので完全無料ではないですけど、あくまで、個人的には非常にリーズナブルに作成できたのではないかと思います。
( 相場がよくわかりませんけど。 私はプログラマ-でもエンジニアでもないので )
直感的な操作が可能:
シンプルなインターフェースと自然言語による操作で、設定さえしてしまえば、以降は初心者でも簡単に使いこなせます。
機械的な出力:
使用した感じでは、人間のようなクリエイティブな出力は期待できないと思います。
単純作業の自動化に適しています。
エラーチェック機能に課題:
自律的ですが自然言語でコーディングするため、エラーチェックおよび対応にやや不十分な面があるようには思います。
例えばimportエラ-などは自己解決できず手動で入れてやる必要がありました。
品質保証には別の工夫が必要でしょう。
教育用途としての可能性:
OpenDevinは、APIの料金がかかるものの、シンプルなコードを学ぶのに非常に有効なツールです。
直感的な操作性とプロンプトからのコード生成機能は、アプリの初歩的な動きを確認するのに理想的な学びの環境を提供してくれます。
この点では、次世代の教育ツールとしての役割も期待できるかもしれません。
実装および実行手順の概略:
Windows10で実行しました。
導入に当たって準備として、以下の3つをインストールしている必要があります。
・Docker
※OSに合わせてDockerをインストール
・Python >= 3.11
・Node.js >= 18.17.1
※この記事執筆時点
githubリポジトリをクローン
git clone https://github.com/OpenDevin/OpenDevin.git
OPENDEVINのサンドボックスイメージの取得
ターミナルを開き、次のコマンドを実行してOPENDEVINのサンドボックスイメージを取得
docker pull ghcr.io/opendevin/sandbox
OpenAIのAPIキーのパスを導入
config.toml.templateを編集して発行したAPIキ-を貼り付けてconfig.tomlとして保存
Python の依存パッケージのインストール
python -m pip install -r requirements.txt
実行手順
バックエンドの起動
先ほどの仮想環境内で、次のコマンドを実行してバックエンドを起動します。
uvicorn opendevin.server.listen:app --port 3000
フロントエンドの起動
別のターミナルを開き、次のコマンドでフロントエンドを起動します。
cd frontend
npm install
npm run start -- --port 3001
OPENDEVINの確認
ブラウザで http://localhost:3001 にアクセスすると、OPENDEVINのインターフェースが表示されWEB UIとして使えるようになります
詳しくは、OpenDevin/README.mdをご覧いただければと思います。
実際の使用画面および事例1( メモ・アプリを作成依頼した件を例として )
以下は、導入後OPENDEVINのインターフェースが表示された後に
簡単な設定をしプロンプトを打ち込んで
丁度メモアプリのコ-ド生成が終わった時の画面です。
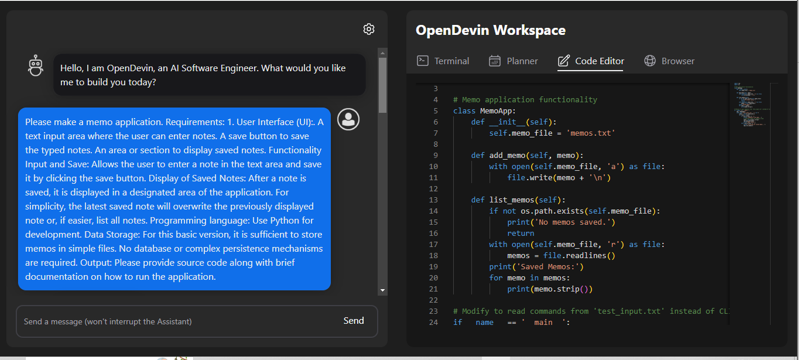
英語のほうが機械学習モデルに理解されやすいようなので
メモアプリ作製の条件および仕様(プロンプト)を日本語で作り、それを英語に翻訳し打ち込みました。
上の画像の青の枠にプロンプトを打ち込んでsendを押すと、プロンプトに応じたアプリを生成するコ-ドを記述してくれます。
sendを押したら、左画面と右画面で、するすると・・・時に止まりながら動作し、およそ2分程度でコ-ドが作製されました。
画面右側に、こちらで依頼したメモアプリのプロンプトに応じてコ-ドが生成されているのがおわかりになると思います。
完了後にOPEN DEVINのworkspaceフォルダを確認するとmemo_app.pyが自律的に作成され保存されていました。
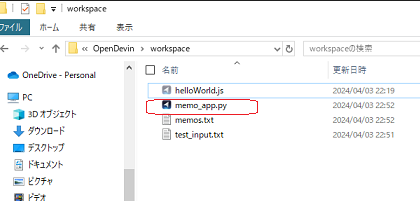
memo_app.pyをコマンドラインで実行したら普通にメモ機能を使えました。
実際の使用画面および事例2( Streamlitを使用して、音声変換アプリを作成依頼した件を例として )
以下はStreamlitを使用した音声変換アプリを依頼した際のコ-ド生成のデモ動画です。
アプリ作製の条件および仕様(プロンプト)を日本語で作り、それを英語に翻訳し左側の画面に打ち込みました。
以下の動画は、無音1分の実に些末なものですが、特に画面の左側の動きに注目してみてください。
人間の介入無しに機械学習モデルが、自己対話して右側にコ-ド生成している様を観察できると思います。
やや恐ろしさすら感じます。(-_-;)
完了後にOPEN DEVINのworkspaceフォルダを確認するとspeech_appliation.pyが自律生成され保存されていました。
デモ動画は途中(1分)までのものですが完了までに約3分ほどかかりました。
ちなみに以下が、OPEN DEVINが自律的に作ったspeech_application.pyの中身です。
この音声認識変換アプリも、先に事例紹介したメモアプリ同様シンプルなものです。
マイクで話した音声を認識して発音してくれるという機能しかありません。
とは言えOPENDevinが自律的に作ったアプリを環境構築した状態でコマンドラインで実行すると
ロ-カルホスト環境で以下のように表示されエラ-なく使うことが出来ました。
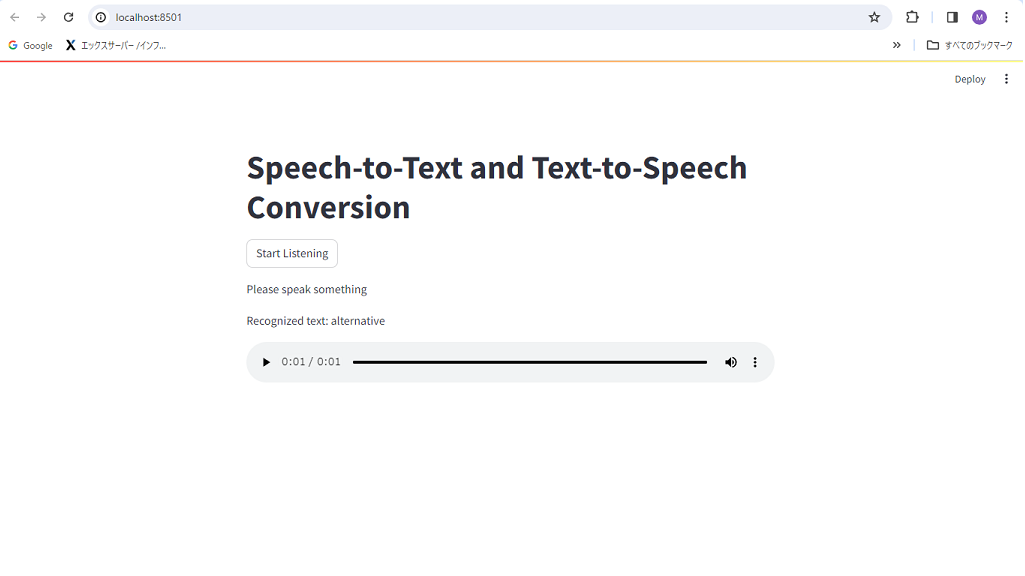
シンプルなコ-ドとはいえ、普通に使えるというのが不思議で本当に驚きです。
ただし、このレベルのアプリならプロンプトをしっかり作ればchatGPT4でも作れると思います。
とは言えOPEN DEVINの場合は、依頼に応じて自律的にコ-ドを実行し
微修正しながらアプリを完成させ、それだけに止まらず
workspaceフォルダに、生成したpyファイルを自らファイルの名前を付けて入れてくれちゃってるというのがChat GPTと違っています。
依頼に応じてtxtなども作って自ら検証し完結させたところも違うところでしょう。
( 尤も今回、アプリを依頼する際のモデルに選んだのは
OPEN AIからAPI取得し運用した有料のgpt-4-turbo-previewです。
よってgpt4が凄いことに変わりはないわけですけど )
非常にシンプルなアプリだからエラ-もデバッグも必要なかったですけど
ソフトウェア開発が自動になるなんて、すごい時代になったものです。
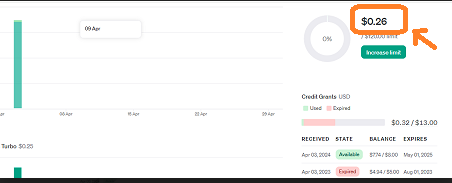
ちなみに今回のメモアプリ作製にかかった費用はAPIの代金 約0.2ドルでした。
以下の画像は0.26ドルになっていますが、0.06ドルは別の小さなプロジェクトで使用しました。
音声認識変換アプリは約0.8ドルの費用がかかりました。